





HashMap
HashMap is one of the collection implementation classes which is a child class of the Map interface. HashMap is the data structure that is used to store the key-value pair objects.
Internal Implementation details of HashMap:
HashMap stores the key-value pairs using a hash table. In the hash table each key-value pair is mapped corresponding to the hashcode
derived from the key. Using the hashing techniques a hashcode is derived from the key and using the hashcode we identify the index in
the bucket list of the hashtable. This bucket list is an array of the lists of key-value pairs corresponding to the hash codes.
Following diagram depicts the clear picture how internally key-value pairs are stored. First hash code is calculated for the keys.
Using the hashcode, index is identified in the bucket array. Corresponding to the hashed index, key-value pair entry is stored in
the list corresponding to that particular bucket.
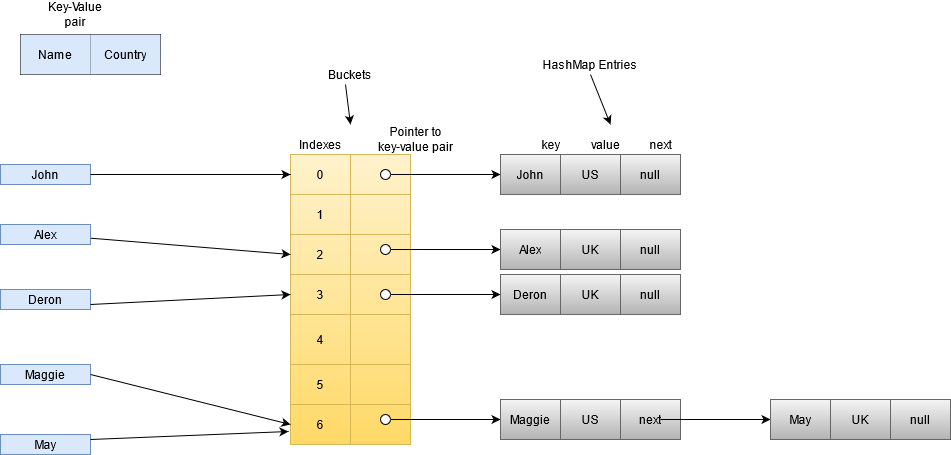
So in HashMap, at the first level we have an array. In the array, each array index is mapped to the hashcode derived from the key.
Each array index ( or we can say each bucket ) contains a reference to a linked list in which we store the key-value pair entry.
For a key-value pair, first identify the hash code for the key using the hashcode() method. Once we have the hash code, index is
calculated to identify the bucket in which the key-value pair will be stored. Once we have the bucket index, check for the entry list.
If we do not have the already existing list corresponding to that bucket index then we create a list and add the key-value pair entry to
the list. And if already there is a list of the key-value entries then we go through the list check for key object if the key already
exist and if key already exist then we override the value. If key is not there then a new entry is created for the key-value pair.
New entry is then added to the list
Important HashMap Parameters :
HashMap’s internal hash table is is created only after the first use. Initially the hash table is null. Table is initialized only when
the first insertion call is made for the HashMap instance.
transient Node<K,V>[] table;
The two parameters that affect the performance of HashMap are – initial capacity and load factor. Initial capacity is the initial size of
the hash table and load factor is is a measure of how full the hash table is allowed to get before its capacity is automatically increased.
Using the below Hashtable constructor, initialCapacity and loadFactor can be passed by a programmer.
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
Using the initial capacity and load factor, threshold is calculated. Threshold is the size limit after which table is resized/rehashed. The value of the threshold is (int)(capacity * loadFactor).)
Threshold and loadFactor fields :
int threshold;
final float loadFactor;
Deafult value for initial capacity is 16 and default load factor is 0.75.
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
static final float DEFAULT_LOAD_FACTOR = 0.75f;
Growing the HashMap bucket :
Using the initial capacity and load factor, threshold is calculated. Threshold is the size limit after which table is resized/rehashed. The value of the threshold is (int)(capacity * loadFactor).)
HashMap Entry classes :
A Node is used as a basic bin node for entries in HashMap.
A HashMap Node is the child class of the Entry interface.
A HashMap Node(Entry) stores hash, key, value and the next node reference.
Hash is the hashcode of the key.
The reference points to the next node in the linkedlist of a particular bucket list.
HashMap also has a TreeNode class that is a subclass of the Node class.
TreeNode is used by the binary tree of a particular bucket.
LinkedHashMap also has a subclass version of the HashMap Node class.
To know more go to - LinkedHashMap section
Node definition:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry e = (Map.Entry)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
TreeNode ( Addition was made as part of the Java 8 updates) :
Usually a HashMap bucket has a LinkedList for key-value pairs. But if the number of entries goes beyond a particular limit that is defined
as TREEIFY_THRESHOLD, then LinkedListed is converted into a Binary Tree( a Red-Black binary Tree ). Using a binary tree decreases the lookup
time for a node. As in case of linked list lookup time complexity is O(n) but in case of binary tree it will be O(log n). Same goes for the
adding/updating a Node.
TreeNode Definition:
/**
* Entry for Tree bins. Extends LinkedHashMap.Entry (which in turn
* extends Node) so can be used as extension of either regular or
* linked node.
*/
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
TreeNode(int hash, K key, V val, Node<K,V> next) {
super(hash, key, val, next);
}
Adding key-value pair to the map using put method :
public V put(K var1, V var2) {
return this.putVal(hash(var1), var1, var2, false, true);
}
Here we pass the key - K var1 and value – V var2.
The put() method calls putVal() method internally, putVal() takes the following arguments :
• hash(var1) - hashCode of the key
• var1 – key
• var2 – value
• boolean false value
• boolean true value
putVal() first check for the HashMap table and if the table is null or empty then calls the resize() method.
And resize() method creates a new table for HashMap.
Resize() method call – initially table is null. So for the first time a new table is created with the default size.
If initial capacity was set using HashMap(int initialCapacity) or HashMap(int initialCapacity, float loadFactor) constructor in
threshold field then initial capacity is set according to threshold.
Otherwise it picks the default initial capacity for the table size.
Default initial capacity of a HashMap is 16 which is defined using
the below HashMap field.
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
In case initial capacity is defined :
int oldThr = threshold; //Threshold is being set in oldThr local field
And then depending on the below condition, in case threshold is greater than 0, it is being set as newCap(new capacity for the table)
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
Otherwise using default:
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
New table is created using the new capacity :
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
In other cases it checks for the MAXIMUM_CAPACITY, if current capacity is more than MAXIMUM_CAPACITY then it resize the table.
After return to putVal : Then if for index value – [(n - 1) & hash], table bucket is empty then newNode() method is called and newly create entry node is placed at the calculated index in the HashMap table.
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
Then checks for the hash value index in the hash table if there is no already existing node then it created a new Node which contains the
hashCode, Key, Value and next node reference in that hash table bucket. Initially it will be null, when a new noide will be added to the
same hash index, then a LinkedList will be formed as the new node with the same hashcode index will be appended next to the previously
added node in a linked list manner using the next field reference.
Getting the value from the HashMap :
We can get the value for a specific key then using get method which accepts a key as parameter.
Internally, get method calls getNode() method. getNode method takes the key and the hashcode of the key as parameters and returns
the corresponding node. Then from the get method, corresponding value is returned.
If node is null or the stored value is null then null is returned.
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
Traversing Through a HashMap :
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map.Entry;
import java.util.Set;
public class TraverseMapUsingEntrySet {
public static void main(String args[]) {
// creating hash map
HashMap<Integer, String> map = new HashMap<Integer, String>();
// Adding key-value pairs to the HashMap
map.put(1, "India");
map.put(2, "US");
map.put(3, "UK");
map.put(4, "China");
Set<Entry<Integer, String>> entrySet = map.entrySet();
//Using entrySet we can iterate over key-value pairs using
//for-each construct or iterator or aggregate functions
//Iterating using for-each construct
for (Entry<Integer, String> entry : entrySet) {
System.out.println("Key = " + entry.getKey() + ", Value = " + entry.getValue());
}
System.out.println();
//Traversing using iterator
Iterator<Entry<Integer, String>> itr=entrySet.iterator();
while (itr.hasNext()) {
Entry<Integer,String> entry = (Entry<Integer,String>) itr.next();
System.out.println("Key = " + entry.getKey() + ", Value = " + entry.getValue());
}
}
}
Using KeySet :
import java.util.HashMap;
import java.util.Set;
public class TraversalUsingKeySet {
public static void main(String args[]) {
// creating hash map
HashMap<Integer, String> map = new HashMap<Integer, String>();
// Adding key-value pairs to the HashMap
map.put(1, "India");
map.put(2, "US");
map.put(3, "UK");
map.put(4, "China");
Set<Integer> keySet = map.keySet();
for (Integer key : keySet) {
System.out.println("Key = "+key+", Value = "+map.get(key));
}
}
}